
你好,我是曹犟。
欢迎来到这门课程的第一部分,在这一部分中,我将帮你了解如何设计一个典型的大数据系统。我们会先用一节课程来了解一个大数据系统的整体架构设计。然后,我们会顺着整个数据流的方向,依次探讨系统的各个环节应该如何设计。在这个过程中,我会尽量以开源组件等公开技术为准,方便你在构建自己的系统时进行参考。
与任何技术系统的设计一样,只有先明确了目标,我们才能根据目标的约束,对方案进行取舍与权衡,最终确定技术设计。
因此,在讨论具体的系统架构如何设计之前,我们有必要先来看看,一个大数据系统设计时,应该有哪些设计目标,它们会对本课程讨论的系统设计哲学有哪些影响。
设计目标与设计哲学
作为一个大数据系统,在设计的时候,需要确定如下的设计目标。
首先是数据类型,也就是系统需要能够采集和处理哪些类型的数据。典型的数据包括结构化数据和非结构化数据。日志、数据库等,是结构化数据,而视频、图片、用户评论等,这些则是典型的非结构化数据。
过往大部分数据系统,都是侧重于结构化数据的处理,而大模型技术带来的多模态处理能力进步,让非结构化数据的处理变成了可能。因此我们的设计目标也是以结构化数据的处理为主,但是会在第 22 节课中专门讨论如何利用大模型的能力处理非结构化数据。
其次是数据量。在过去十多年,随着 Google 从 2003 年开始陆续发表的关于 GFS、MapReduce、Bigtable 这三篇论文,以及以 Hadoop 三驾马车为代表的一系列开源分布式系统的成熟,使得对于海量数据的处理技术得到了巨大的普及,处理 TB 级、PB 级数据,不再是互联网巨头的特权。同时,随着移动互联网和物联网的蓬勃发展,数据的生产能力也得到了指数级的提升。因此课程中,我们设计的数据系统默认需要有海量数据的处理能力,并且能够具有相当的水平可扩展性。
第三是时效性。在过往,大数据的应用主要以为人提供决策依据为主,对于数据处理的时效性要求并不高。但是,随着个性化推荐、计算广告学的发展,数据不仅仅可以驱动决策,而且可以直接驱动业务。而这些业务应用对于数据的时效性通常需要到秒级甚至是毫秒级。考虑到通用性,我们设计的系统还是以秒级时效性处理为主。但是会在第 21 节课讨论推荐和广告系统时,覆盖到毫秒级时效性系统的设计。
第四是成本。虽然在过去十年间,随着摩尔定律的延续,存储、网络、CPU 等硬件成本有了巨幅下降,但是数据量和时效性要求也在提升,这给硬件成本也提出了更高的要求。同时,系统本身的开发成本也是不可忽视的。因此,我们课程里会尽量以使用免费的开源技术方案为主,同时,也会尽量考虑对硬件成本的控制。
第五是安全与隐私。随着 GDPR、个保法等安全、隐私方面法规的发布与完善,一个大数据设计系统在设计之初就需要考虑到安全与隐私保护,并且这种保护应该是贯穿在整个数据流和系统架构各部分的。
第六是可维护性。从我个人过去接近二十年的大数据系统实践经验来看,一个大数据系统的建设期,由于有充分的预算与准备,通常是比较容易得到一个较好的结果。但是,大部分系统在持续运行一段时间之后,通常会由于缺乏实际的维护,而会变得逐渐不可用。因此,我们后续也会重点讨论一下如何设计出更具有可持续性、更容易维护的大数据系统。
取舍与权衡
没有一种架构能够完美地满足所有需求,系统设计的核心是权衡。在有了具体的大数据系统设计的目标后,我们来聊聊如何根据这些目标做取舍。
一个大数据系统,通常需要在五个方面做出计算决策。
首先是一致性、可用性、分区容错性的选择。根据 CAP 定理,分布式系统只能同时满足以下三个特性中的两个:一致性(Consistency),所有节点在同一时间看到相同的数据;可用性(Availability),系统保持可操作状态;分区容错性(Partition Tolerance),系统在网络分区时仍能继续运行。
从之前我们设定的设计目标上看,我们需要尽可能节省成本,并且能够涵盖巨大的数据量同时,具有很高的水平可扩展性。而作为大数据系统,我们的应用主要以决策支持和推荐、广告等应用为主,对于数据的准确性并没有极端严格的要求。因此,我们设计的系统更应该是一个 AP 系统,优先保证数据可用性,数据的一致性以最终一致性为目标,即可以容忍数据暂时的不一致。
其次是批处理与流处理的选择。批处理的优势是高吞吐量,适合处理大量的历史数据,计算资源利用率高,实现相对简单,容错性好。而流处理的优势则是低延迟,实时响应,适合处理连续数据流。
从我们确定的设计目标上看,我们应该设计一个批流一体的数据处理系统。系统首先需要能够以很好的时效性来处理新产生的数据,以便满足下游应用的时效性需求。同时,对于历史数据等需要批处理的数据,也应该有能够兼顾的处理方案。
第三是 OLTP 和 OLAP 的取舍。OLTP 系统,如 MySQL 等,是为了事务处理而优化的,通常使用行存储,支持高并发的写入和高 QPS 的查询。而 OLAP 系统,如 Doris 和 ClickHouse,是为了分析性查询而优化的,通常采用列存储,能够支持巨大扫描量的查询,能够支持高吞吐的写入,但是通常查询 QPS 会有限制。由于大数据系统的典型应用对于事务要求并不高,同时由于数据量的巨大,迫切需要使用列存储技术来减少 I/O 吞吐,所以我们应该以 OLAP 和列存储为主要选择。
第四是数据质量和处理速度的权衡。如果为了保证数据质量,通常会有多层次的数据校验、严格的 Schema 管理。而如果为了保证处理速度,则应该最小化数据校验,采用类似于 Schema Free 的宽松管理方式,并且通常会有更多的异步处理机制。从一个大数据系统的设计实践来看,我们应该以保证处理速度为首要选择,而对于数据质量,则可以考虑在主干路上以不太影响速度的简单匹配规则为主,辅以旁路上的重度处理。
第五则是所有系统都会面临的、永恒的成本与性能的选择。例如,是选用更便宜的对象存储,还是选择更快但是更贵的 SSD,是使用弹性计算资源,还是预留计算资源等等。这方面则很难有统一的结论,我们会在后面详细学习系统的每一部分时,来具体讨论。
总的来说,对于大数据系统,由于它独特的应用场景和下游的要求,我们做出了一些重要的技术取舍。整体来说,就是业务需求决定产品设计,产品设计决定技术选型,而技术选型所带来的技术限制,也会反过来影响产品的具体实现,从而对业务的实际应用带来影响。在这个过程中,系统的开发者和使用者,应该充分沟通,互相理解,互相体谅。
逻辑分层
在明确了技术选型与取舍之后,我们可以大致勾勒出一个典型大数据系统的逻辑分层。
现代大数据系统在设计上通常采用分层架构设计,每一次都有它特定的职责。下图展示了典型大数据系统的分层设计,为了后续讨论时聚焦重点,所以设计图做了简化。
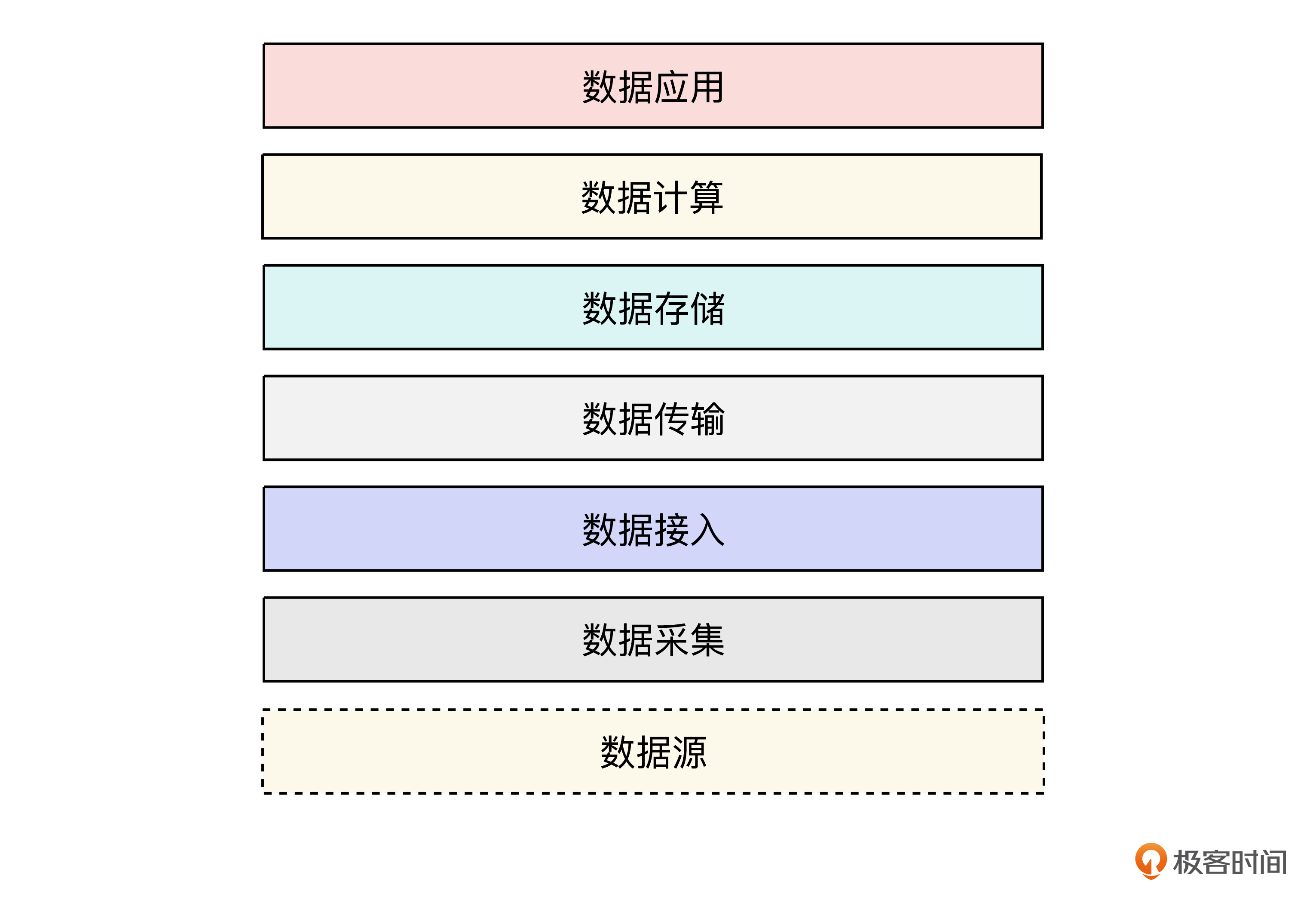
我们从底向上依次进行介绍。
数据源,主要就是指系统需要处理的系统外的各种异构的结构化或者非结构化的数据来源。而数据采集这一层,则是针对不同类型的数据源,应该采取哪种具体采集方案(数据采集方案的设计我们接下来的两节课还会展开讲解)。
在采集到数据之后,考虑到实时应用的需要,通常会将数据发送到接入层。接入层在对数据进行必要的处理后,对于批处理应用,则是将数据写入到数据存储中;对于流式应用,则通常会省略掉存储这一部分,直接对数据进行计算,以满足后续的应用。
数据传输层在这个过程中起着类似于 “数据高速公路” 的关键作用,负责将经过接收层初步处理的数据,高效、可靠地传输到数据存储层或数据计算层。
对于离线系统,数据存储的设计至关重要,是整个数据系统的核心部分。不同的应用和数据类型,决定了不同的存储选型。而在现代大数据系统中,由于需要同时兼顾不同的数据类型和应用类型,类似于冷热数据分离、读写分离等复合型的存储设计,也慢慢成为主流。感谢开源系统的发展带来的技术普惠,此时此刻我们有着多种系统可以选择,这种便利前所未有。
系统的计算层具有两重意义。一方面是对数据本身的进一步加工与处理,处理后的数据还会写入到存储层。一方面也是为了满足不同类型的应用的需要。因此在设计计算层中,我们需要考虑如何兼顾这两大类应用。而在现代大数据系统中,存算一体和存算分离这两种不同的设计思路各有自己适用的场景,我们需要加以了解。
数据系统的可能应用非常丰富多样。但是在充分抽象后,系统的对外出口倒是可以划分为给人用的产品化界面、给其它系统用的 OpenAPI 以及给 AI 用的 MCP 协议。三种不同的接口,需要根据实际的应用类型做出不同的设计。
好,我们已经梳理好了一个典型大数据系统的逻辑结构的大致设计。需要补充的是,例如元数据、调度、监控告警等,我们这里暂且省略了,后面再逐步补充。同时,在实际的设计中,上图中的不同分层有可能会有进一步的整合和分化,建议在后面探讨不同类型的应用案例时,你也可以留意一下不同细分产品的设计区别。
真实案例:从日志统计到用户数据仓库
这节课的最后部分,我想给大家分享一个我自己在百度亲身经历过的真实案例,看看在十几年前大数据的蛮荒时代,一个大数据系统,是如何投入使用,然后在实践的探索中逐步迭代演进到接近现代大数据系统的。
2008年,Google 大数据三驾马车论文刚刚发布还没多久,Hadoop 等开源系统刚刚进入国内,百度是国内最早一批尝试讲这些开源技术落地应用的公司。那时候我刚进入百度,参加了内部一个基于 Hadoop 的数据应用项目—— Log 平台。
在这之前,百度内部不同业务线的日志,都是单独存在于前端服务器的,将这些日志会被统一下载到集中的几台日志服务器中,然后维护了很多脚本,用于对这些脚本进行统计,然后用 Email 发送给关心数据的人。具体架构如下图所示:
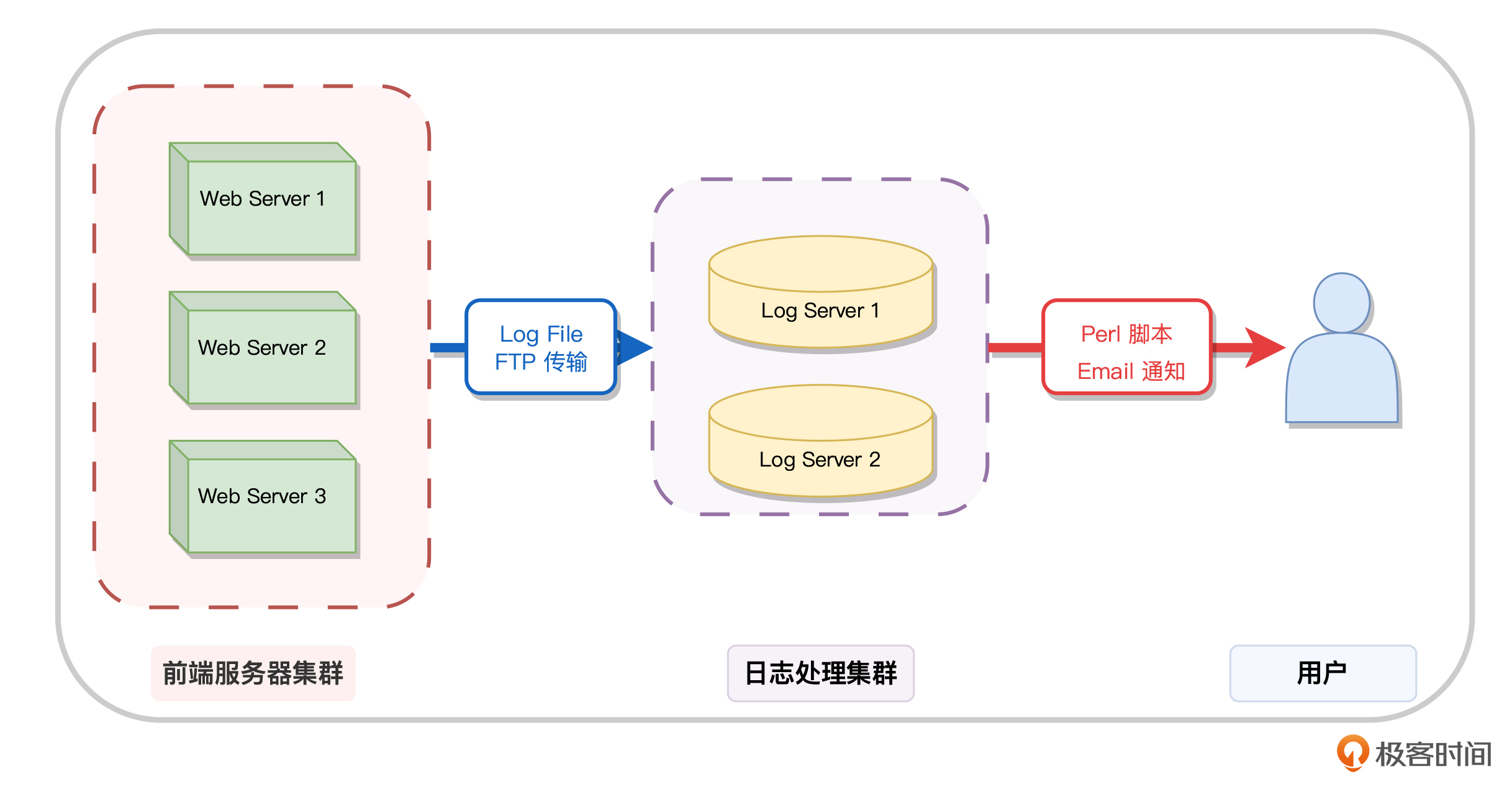
用现在的角度看,这是一个开发效率很低、很难扩展也很难维护的方案,而当时百度内部,正好在给 Hadoop 寻找应用场景。因此,内部立项了 Log 平台这个项目,将这些日志文件统一汇总到 Hadoop 平台上,然后用 MapReduce 任务来对日志进行统计和计算。具体架构如下图所示:
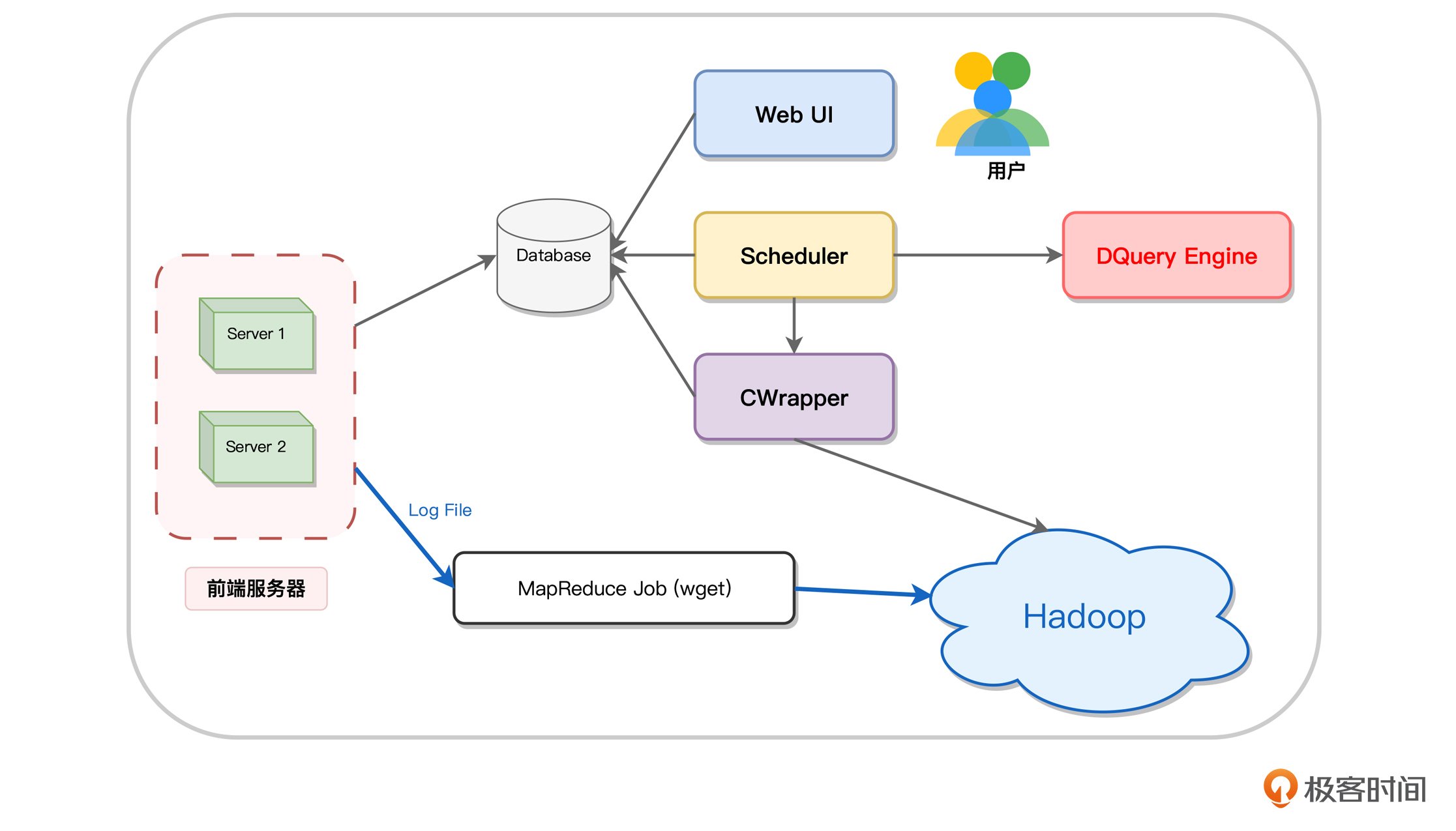
当时的计算引擎远没有现在这么丰富,因此,我们一方面是对常见的统计算子进行了抽象,提供了页面配置的方案。
另一方面,也发明了一个类似于 Hive 的计算语言 DISQL,用于日志的统计和处理,如下面这个代码片段所演示的那样。
DQuery::input()
->select(array('_Site','_Url'))
->group('_Url')
->countEach('_Url','_UrlCnt')
->outputAsFile('pv_per_url','分 URL 访问统计');
平台上线之后,广受好评,到了 2011 年前后,很快就覆盖了百度内部所有用户日志相关的统计和报表业务,平台所占用的计算资源,也迅速从几十台增长到了 5000 台。
但是,由于缺乏开发和维护一个大数据平台的经验,平台本身也存在很多问题。
-
缺乏对于数据 Schema 的控制和数据血缘的管理,导致重复数据和计算极多。
-
不同计算任务之间也没有办法进行合并。
-
平台只能支持对于日志的统计和产出报表,无法支持 adhoc 类型的交互式分析。
因此,在 2011 年之后,我们开始将 Log 平台重构为百度内部的用户数据仓库,简称 UDW,开始从以计算为中心变成以数据为中心。
我们首先参考了传统数仓的设计思路,将数据做了分层,包括文本日志层、结构化数据层、UDW 层、数据集市层和可视化层,如下图所示:
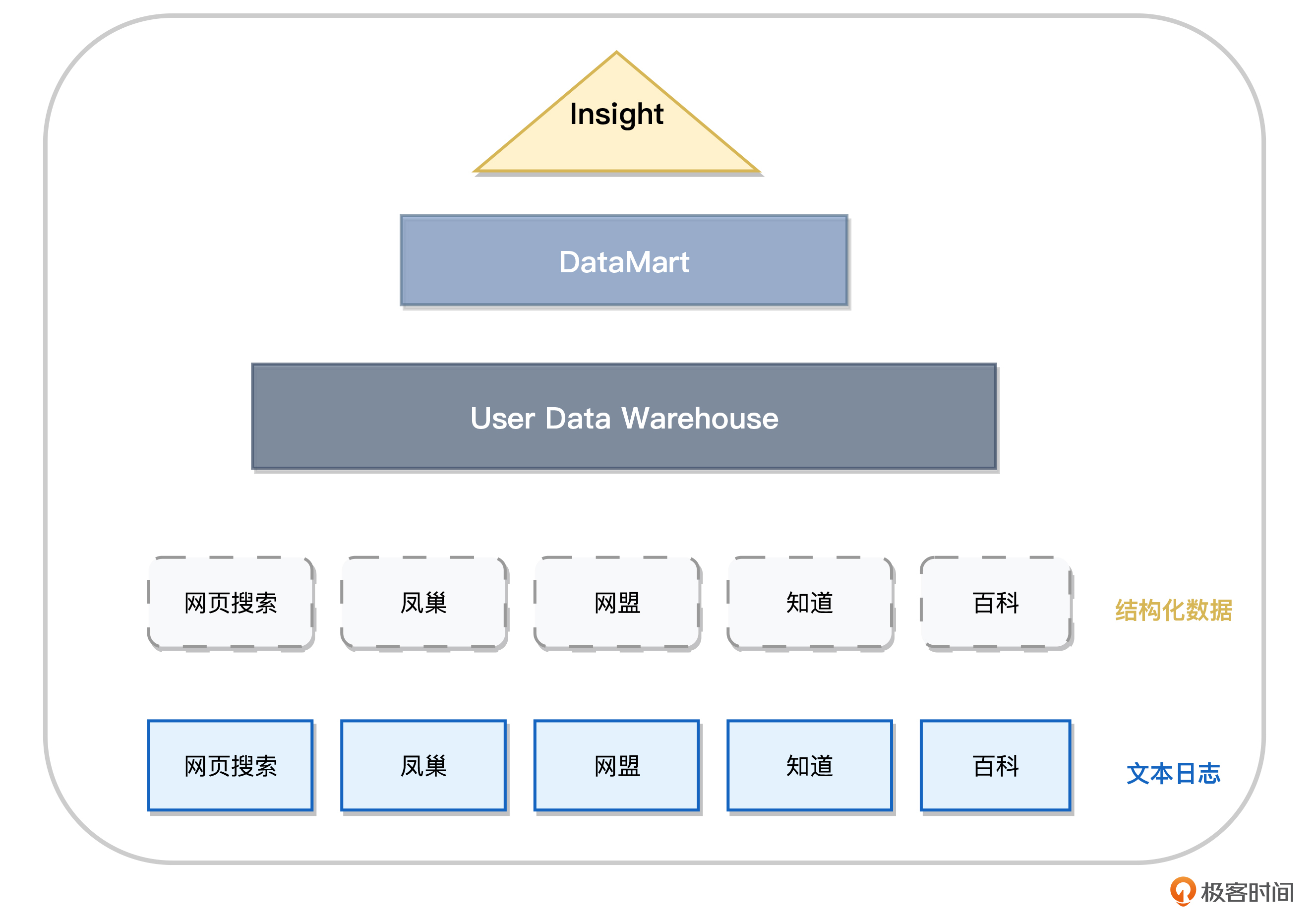
在这个技术架构上,我们的将系统分层了数据生成、传输、入库、查询分析、可视化几个部分。
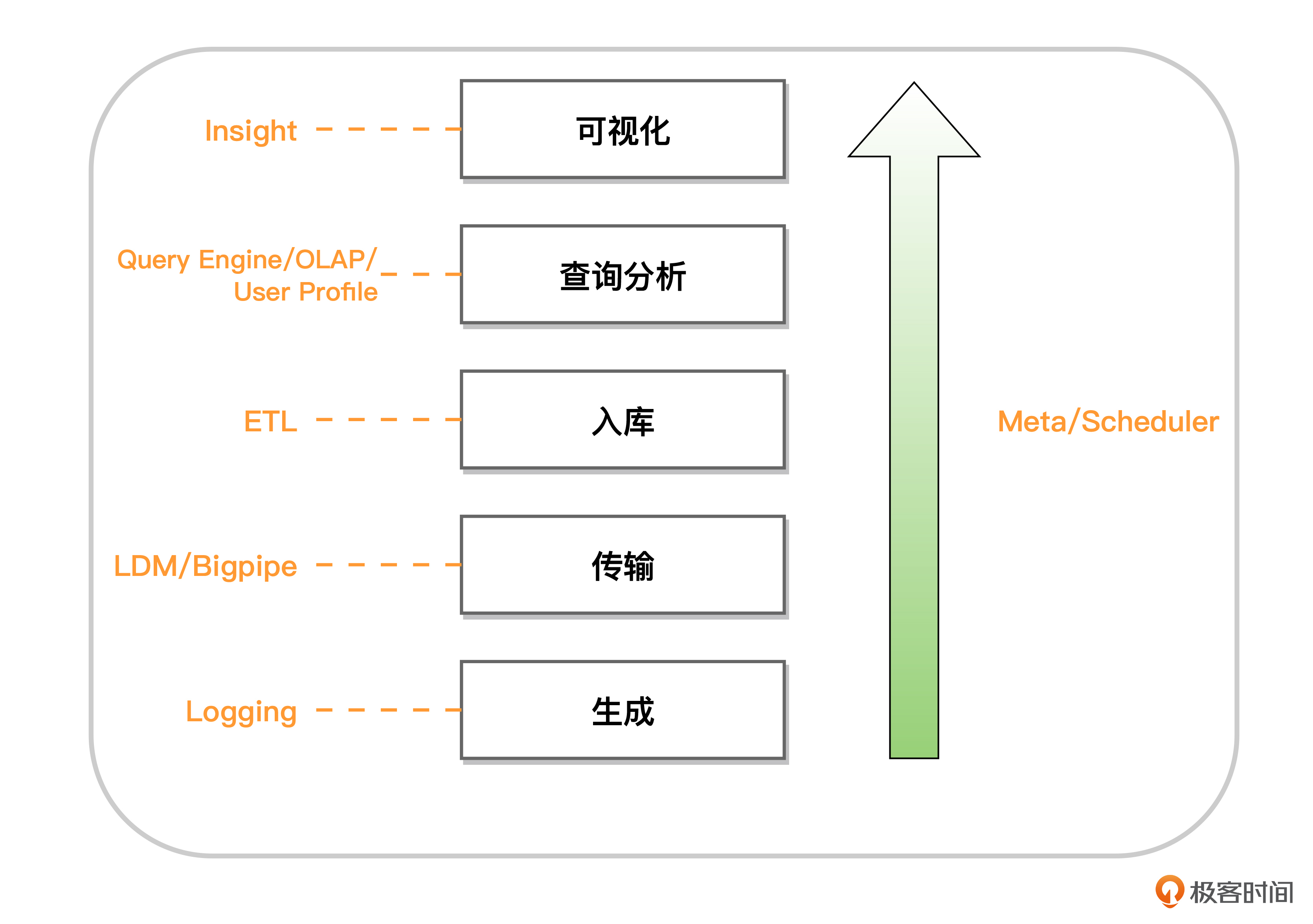
这个架构设计,已经很接近当前主流大数据系统的设计了。同时,在随后的几年里面,为了能够支持广告、个性化推荐等应用,我们在这个架构的基础上,基于百度内部一个实时计算引擎 Dstream 和一个类似于 Redis 的 KV 存储引擎 Mola,为系统增加了流式链路,能够在秒级完成对一条用户日志的处理,对用户标签进行实时更新,然后响应下游几十万 QPS 的点查请求。
在第一节课中分享这个案例,更多还是想从我个人十几年前亲身经历的过程中,方便你体会如今的大数据系统的典型架构,是如何在实践过程中一步步演进迭代的。
课程总结
在这节课中,我们讨论了大数据系统的设计目标和设计哲学,以及我们应该如何根据目标进行具体的技术取舍,希望你能够仔细体会。
同时,我们也给出了一个典型的大数据系统的逻辑分层,而在第一部分剩下的几节课中,我们会依次对它们进行更详细的介绍。比较特别的是,数据应用层由于与具体的应用耦合比较紧,我们会在第三部分讲解具体的应用案例时来展开介绍。
学完今天的内容,对于数据产品经理和数据开发工程师来说,当我们面临一个业务需求,需要从头开始进行大数据系统的技术架构和数据流设计时,我们心里面就能有一个大致的框架可以参考。我们可以在这节课的基础上做裁剪和修改,来适配自己的业务需求。
对于数据分析师和产品经理来说,我们一般情况下是大数据系统的使用者。初步了解大数据系统的技术设计,对于提出合理的数据和产品需求,以及与开发同事高效沟通,也是非常有必要的。
思考题
-
除了大数据系统之外,你还接触过哪些复杂的系统?它们在做设计取舍时的依据是什么?
-
你过往工作中的大数据系统,是否符合本节课中提到的逻辑分层划分?如果不符合,是因为什么考虑呢?
期待你在留言区分享你的思考。如果这节课对你有启发,也推荐你把它分享给身边更多朋友。